What does the AI bubble tell us about the antitrust challenges ahead?
Regulators should be worried about the message implicit in investors' expectations encapsualted in AI and "halo" stock prices
Tony Curzon Price, 3/7/24
There is a puzzle about what exactly is maintaining such investor confidence in AI-halo stocks, given how uncertain the business models around AI still are. I will propose an explanation for the beliefs that are consistent with the speculative activity we are seeing around AI that will be grounded in an analysis of market power and a coming redistribution of rents in the platformised tech sector. This hypothesis points to antitrust battles ahead, and, if the speculators valuations are justified, they are banking on antitrust failure. So what do regulators need to do to prove them wrong?
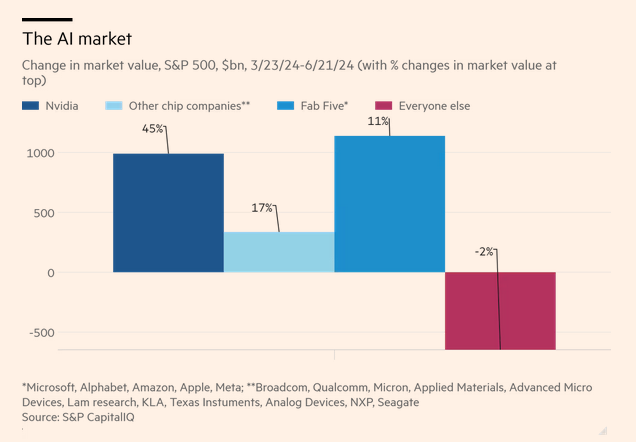
Robert Armstrong, in his consistently excellent FT Unhedged column, has been wondering about the speculative AI bubble that is gripping stock markets. In a series of 3 fascinating notes, he has pointed to the extraordinary role that the AI-halo has played in sustaining the SP&500. He pointed out last week that the S&P500's solid recent performance is largely due to NVidia, MAAAM (Microsoft, Apple, Amazon, Alphabet and Meta), other chip companies … and has been pulled down by everyone else. The outsize role of NVidia, which currently holds the chip chokehold on AI deployments, is particularly noteworthy.
This week, Armstrong noted that Apple, after announcing its integration of OpenAI into its iOS AI integration, has thereby joined the MAAAMs as an AI stock. But why, he wonders? As he points out, the features revealed under the banner of “Apple Intelligence” are hardly so amazing as to lead to actual hugely increased spending by the Apple faithful: “Proofreading and editing tools; emoji customisation, image building, better language interpretation for the Siri digital assistant, all with the usual Apple-y promises about privacy. Nothing here seems likely to drive a device upgrade cycle among consumers.” Surely this is not a list worth $600m more capitalised profit?
For Armstrong, all of this is a pretty clear indication that we're in the irrational exuberance phase of AI deployment:

Remember that 2023 Google memo about "we have no moat?" The thesis expounded there was that Google did not have a long term barrier to entry in LLMs, and that Open Source tools were quite likely to outdo the closed source technologists in innovation. I largely think that this is more or less turning out to be the case. We have technologically competitive tools that have emerged from Anthropic, Perplexity & Mistral as well as the ones from Google and OpenAI … and there are any number more foundational and specialist models that have been released or are in the works. Of course, there is also Meta’s even more open source Llama, which is developing an ecosystem of applications and exploration.
I am not saying that full, Linux-style open source will in fact be the rule in large AI models. Perhaps it will. I hope so. But these machines are very expensive to train and most teams will be asked for a plan to get to revenues. But what we have seen is an oligopoly emerging - several large providers of somewhat substitutable goods. Moreover, these are goods that have huge, sunk capital costs, which means, in competitive terms, that price competition in a commoditised market will have a real risk of under-recovering those costs - this is the old Bertrand competition argument.
For Google, it seems to me it is even worse than "having no moat" in LLMs themselves - they actively destroy the moat that it has long held in search. I am sure I am not unusual in having very painlessly got into the habit, lately, of triaging which searches go where: is this one of Perplexity, for OpenAI, for DuckDuckGo, for Google, for Amazon or for EBay. This mental habit of coming to sense what best suits this particular informational need is bad news for Google's central business of search advertising: Google really is no longer the default choice.
So how does this account of what LLMs are doing to web habits fit with Armstrong's "AI Halo" mystery? If we are moving to Bertrand competition in many software tasks, including search, why are we not seeing a melt-down amongst existing platforms that rely on monopoly positions in search, data gathering and attention for their rents?
Here is my hypothesis: a good portion of the rents from the old platform models are indeed now up for grabs. The question is who will collect them? NVidia is a very good medium term bet: if the platforms are slugging it out hoping for a moat to emerge, their weaponry of choice for now is NVidia GPUs. They believe that scale might bring them winner-take-all rewards, and they will, if necessary, spend their entire current rent on trying to achieve it. So the arms dealer is quite rightly doing well. (But so are start-up chip companies (eg Etched) and potential rivals like AMD, who could make products more suited to the war than NVidia. A lot, therefore, hangs on the reality or not of NVidia's software moat with its CUDA library).
NVidia may or may not maintain its chokehold position at the top of the AI supply chain. But where else will the rents that the platforms currently enjoy from their current data+attention monopolies go?
Certainly some will go into covering the cloud computing costs of the new LLM/Search war. This will benefit the current cloud oligopolists - Amazon, Microsoft & Google. But note that cloud is a classic oligopoly, not the complete monopoly that any of these three has in their respective sovereign domains: real-world retail, business operating systems and software, and advertising. This is not to say all is good in cloud competition (far from it - see the CMA inquiry's very credible Issues Statement), but it is certainly better, and a more classic antitrust problem, than is the case in their core monopolies. So, as Armstrong points out in his second piece, some of the old platform rent, through the LLM wars, is being poured into the cloud providers - the old platform monopolists - except Apple - also happen to be arms dealers. That explains a bit of the AI halo, and it explains why GAM should be feeling so much less of it than NVidia.
So who else will get some of the old rent? Investors seem to have come to the conclusion from Apple's OpenAI deal that quite a lot will flow Apple's way. This - absent antitrust work - seems a sensible conclusion. The Apple/OpenAI deal is one in which Apple does not pay OpenAI. In this sense, it has the feel of the Apple/Google search deal, where Apple uses its “ownership” of a user to direct them to another's service … and in the case of search, with its well-established business model, Apple charges a tidy sum for the privilege. Apple is not (yet) charging OpenAI for access to its customers. However, it made clear that other LLM providers will possibly be able to benefit from the Apple/iOS firehose of users in the future. Perhaps Apple will even run Llama on its own cloud to serve customer requests that cannot be served on-device… What this suggests is that with LLMs, as with other value on the web, whoever owns the user interface owns the eyeball, and whoever owns the eyeball can extract a good share of its rent.
So where does this leave us in terms of the way that the all-out (economic) war that LLMs have unleashed will redistribute rents? Well … the eyeball owners are Apple, Microsoft (through its grip on the corporate user), Meta, through its ownership of social media, Alphabet because it controls Android & Chrome, and Amazon because it owns shopping. So there we have it: MAAAM is back, but not for the old reasons. Note however, that MAAAM as a whole should hardly be considered to be in-line for a great deal of growth in profits if my story is correct: of the attention+data rents that are available today, they will have to share a large piece with NVidia, which previously had no seat at the table. So I am certainly with Armstrong's irrational exuberance hypothesis.
This is what explains the shifting sands of the "AI Halo", I think - NVidia almost certainly wins from war, and MAAAM could turn its ownership of the end-user into an opportunity to share the old rents with the main arms-dealer.
But what of the consumer and citizen in all of this? The whole point of disruptive competition, the one that brings down big moats, in the textbook telling of it, is that it hands a whole lot of value to consumers. They are meant to sit patiently while rents are harvested by monopolists to see them pulled down and eventually distributed their way… But if the account I have given is correct, investors are anticipating a reshuffling of the monopoly rents, not their disappearance.
So what is going wrong?
In classic antitrust terms, the NVidia situation needs an active watching brief. If entry is not successful soon, one of the big authorities ought to investigate and presumably do something like force the divestiture or FRANDing of CUDA. (I don't believe the chip design part of NVidia's advantage, however impressive, is actually sustainable in the medium term).
But much more worryingly, in my view, is the assumption that investors seem to be making: that MAAAM still has ownership of the end-user, and that the disruption to search will not in fact turn into an end to the eyeball+data monopolies. This is what should be of most concern to regulators about the "AI Halo." Despite all the talk from the EU's Digital Markets Act and AI Act teams that Ai will not be allowed to repeat the monopolising mistakes of the platform era, investors are ignoring them. Despite the UK CMA's diligent watchfulness over emergent market power in the LLM space, investors do not seem to believe that disruption will benefit consumers or citizens directly.
So what should regulators be doing? In my view, consumers and citizens will get a seat at this table when we find an expression in policy to two fundamental points:
- We ought to be masters of our own attention - we should have ultimate control of what is presented to us for consideration through our screens & other UIs
- Data, as an almost zero marginal cost factor of production, should be maximally available to the human commons, and restrictions on its availability should be on the grounds of privacy or security (or other real collective externality, like the incentive to original production) not on the grounds of the profitability of withholding it.
If proper regulatory reality were given to the first of these, then the $600m of capitalised profits investors are envisaging for Apple will become consumer surplus instead. And if the second were given proper regulatory grounding, then the moat that might arise from exclusive access to certain datasets, like the clickstream, would not exist.
To my mind, these require less of a traditional antitrust approach, and more of an approach based on developing a system-wide architecture of data standards, rights and obligations that leads to a good overall set of incentives in cyberspace. What the blueprint is for this will be for a future post. A big part of the standardisation part has to go through the reinforcement of the meaningful consent principle at the hear of GDPR, but mediated through delegated civil society organisations like Data Unions (I have sketched out the logic of this over here). The open technical standards that can support this exist already - for example Sir Tim Berners-Lee's Solid protocol, which is being made ready for nation-scale deployment by Inrupt, the start-up he has established alongside the open standard.
The blueprint, in other words, is there and is ready for deployment. Sadly, I don't think that investors think this is coming any time soon.